欢迎您访问广东某某机械环保科有限公司网站,公司主营某某机械、某某设备、某某模具等产品!
全国咨询热线: 400-123-4567



 新闻资讯
新闻资讯 哈希游戏| 哈希游戏平台| 哈希游戏APP
哈希游戏| 哈希游戏平台| 哈希游戏APP哈希游戏- 哈希游戏平台- 哈希游戏官方网站让我们先简单回顾Engram的源起,它出现在公众视野,是源自DeepSeek联合北京大学发布的论文《Conditional Memory via Scalable Lookup》。业界对它的评价,是为“破解万物皆推理”模式引发的大模型的记忆困境提供了全新思路。这里提到的记忆困境,指的是宝贵的算力被消耗在本可直接调取的静态知识检索上,这不仅会拖慢响应速度、增加推理成本,还让大模型在复杂任务上的性能突破陷入瓶颈。
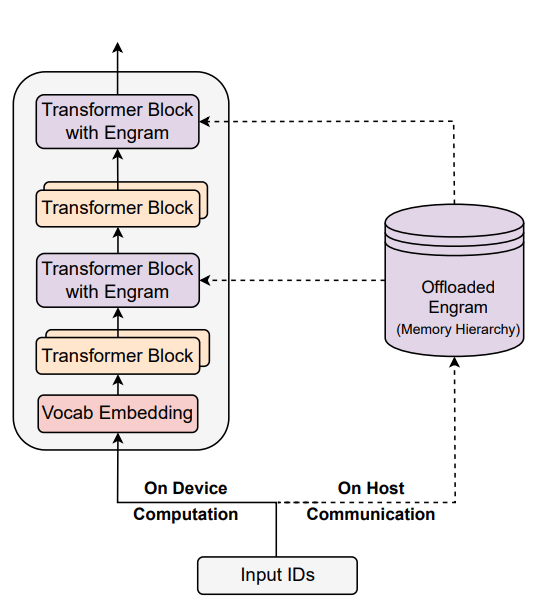
Engram将“查算分离”落到实处的做法,就是把大模型里的“计算”和“超大规模记忆”解耦,Transformer的算子全部在GPU/加速卡上计算,而庞大的Engram Embedding表放在CPU内存或高速存储设备上存查。如图1所示,GPU与CPU分工合作并通过异步方式协同,GPU执行前一步计算的同时,CPU可提前预取后续计算所需的N-gram Embedding表,当计算执行到“Transformer Block with Engram”时,所需的静态知识已经就位。
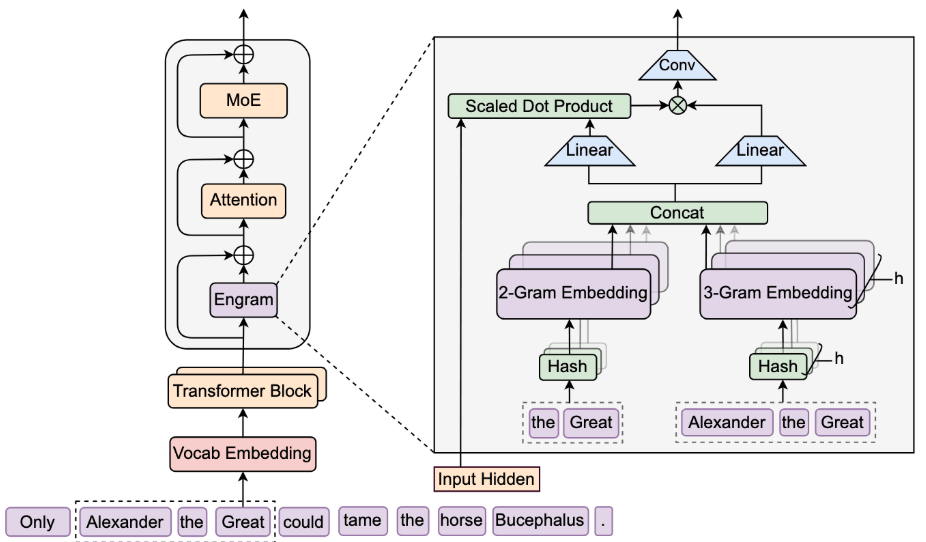
动态门控融合阶段:N-gram 嵌入表先经Concat(通道拼接)形成融合记忆向量,再通过两个Linear(线性转换)层分别投影为Key(记忆语义摘要)与Value(待注入信息)。随后将当前Transformer层的Input Hidden(全局上下文)与 Key 做 Scaled Dot Product (点积计算)生成门控权重,动态过滤与上下文无关的Value信息。加权后的Value再通过Conv卷积计算完成局部融合。
在Engram相关论文发表,DeepSeek开源上述流程的Demo代码后,不少业内专家和机构都开展了相关的复现、验证及测试工作。我们的探索则更进一步——不同于原论文中Concat之后的工作任务将交还给GPU执行,我们不仅将N-gram哈希检索阶段的计算放在至强® 平台上执行,还将动态门控融合阶段中的Linear转换计算和Conv卷积计算也放到该平台上运行。换言之,我们是基于充分的性能调优,尝试用CPU平立运行和加速整个Engram模块。
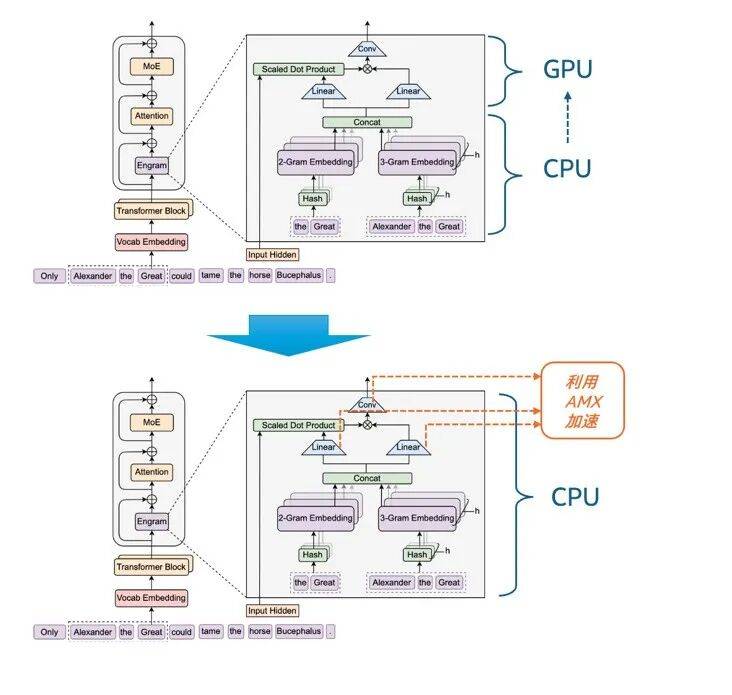
基于此,我们着手在Linear转换计算和Conv卷积计算中利用AMX技术开展了性能加速。具体来说,在Engram中,两个Linear转换计算分别需要处理大量维度映射的矩阵乘法,而AMX的专用矩阵计算单元可并行处理多批次、长序列的高维矩阵乘法,且单条指令可完成更大规模的矩阵运算,运算效率远超传统CPU计算或向量计算(如AVX-512)。在Conv的 short_conv(短卷积)计算中,AMX的矩阵运算能力也可针对短卷积的“小窗口、高并行” 特性实现优化。此外,AMX还对BF16/FP16/INT8等不同的数据格式有着良好支持,能进一步提升矩阵运算加速的性能与灵活性。
